Wenn man lokal ein paar Services hosted, dann möchte man natürlich trotzdem SSL Verschlüsselung nutzen – zum einen um einfach die ständigen Sicherheitswarnungen vom Browser zu unterbinden, aber auch da man einfach keinem Netzwerk blind vertrauen sollte – selbst dem eigenen. In meinem Fall kam dann noch hinzu, dass manche iOS Apps zwingend nach gültigen SSL Zertifikaten verlangen.
Lokale SSL Zertifikate sind self-signed bzw. Selbst-Signiert. Normalerweise werden Zertifikate von diveresen Anbietern im Netz gegen Geld angeboten, damit diese sicherstellen, dass man auch die Person/Firma ist, die man vorgibt zu sein. In den letzten Jahren hat Let’s encrypt diese Abzocke endlich beendet und das ganze kostenlos gemacht, indem die Verifizierung automatisiert per DNS+HTTP Abfragen automatisiert werden konnte.
Alle diese Anbieter funktionieren nur, weil Betriebssysteme und Browser diesen Stellen vertrauen und damit Zertifikaten, die von diesen sogn. root certificates beglaubigt wurden, auch vertrauen . Dabei ist das root Zertifikat in der Regel unendlich lange gültig, alle Sub-Zertifikate die von dieser Stelle ausgegeben wurden sind jedoch in der Regel zeitlich begrenzt.
Dieser ganze Hokuspokus wird erstmal nur gemacht, um Vertrauen herzustellen und sicherzustellen, dass wenn ich google.com aufrufe und dort steht, dass die Verbindung gesichert ist und der Gegenstelle vertraut wird, dass dem auch so ist. Damit wird z.b. verhindert, dass ich zwar mit einer Website spreche, die behauptet google.com zu sein, aber eigentlich ein Man-in-the-middle Angreifer ist, der mich verdeckt auf einen anderen Server geleitet hat.
Denn unabhängig vom Vertrauen kann man natürlich die Verbindung mit den Zertifikaten verschlüsseln, nur bringt das eben nicht viel wenn ich nicht weiß, ob mein Gegenüber das richtige Gegenüber ist.
Das erstmal zu den Grundlagen.
Das Vorgehen für lokale Self-Signed Zertifikate ist etwas anders: Zunächst erstellen wir uns eine CA, also eine eigene Ausgabestelle für Zertifikate. Anschließend müssen wir diese CA auf allen unseren Geräten hinterlegen und ihr das Vertrauen aussprechen. Ab diesem Moment können wir damit neue Unterzertifikate erstellen, denen dann auf allen diesen Geräten automatisch auch vertraut wird und eine SSL Verbindung zustande kommt.
In meinem Fall wollte ich das ganze so einfach wie möglich halten und habe mich daher für ein Lokales Wildcard Zertifikat (*.bytelude.intern) entschieden.
Die Schritte dafür sind folgende:
Zertifikate erstellen
1. CA Key und Cert anlegen (bitte ein sicheres Passwort verwenden, wenn danach gefragt wird und dieses sicher hinterlegen!):
openssl genpkey -algorithm RSA -aes128 -out private-ca.key -outform PEM -pkeyopt rsa_keygen_bits:2048
openssl req -x509 -new -nodes -sha256 -days 3650 -key private-ca.key -out self-signed-ca-cert.crt
2. Key und Certificate Request für das Bytelude Unterzertifikat anlegen
openssl genpkey -algorithm RSA -out bytelude.key -outform PEM -pkeyopt rsa_keygen_bits:2048
openssl req -new -key bytelude.key -out bytelude.csr
3. Config für das Bytelude Unterzertifikat anlegen. Inhalt der Datei bytelude.ext:
authorityKeyIdentifier=keyid,issuer
basicConstraints=CA:FALSE
keyUsage = digitalSignature, nonRepudiation, keyEncipherment, dataEncipherment
extendedKeyUsage = serverAuth
subjectAltName = @alt_names
[alt_names]
DNS.1 = *.bytelude.intern
# Optionally add IP if you're not using DNS names:
IP.1 = 192.168.1.3
Sowohl für den DNS als auch den IP Eintrag könnt ihr mehrere Einträge mit fortlaufender Nummer machen.
4. Bytelude Unterzertifikat erzeugen
openssl x509 -req -in bytelude.csr -CA self-signed-ca-cert.crt -CAkey private-ca.key -CAcreateserial -out bytelude.crt -days 365 -sha256 -extfile bytelude.ext
Dieses letzte Zertifikat ist nun das konkrete Zertifikat, welches ihr z.B. im Webserver hinterlegt. Dieses ist in diesem Beispiel ein Jahr lang gültig und muss dann erneuert werden – dafür reicht dieser letzte Befehl aus, sofern die restlichen Dateien noch da sind.
Die Datei “self-signed-ca-cert.crt” ist das Zertifikat, welches ihr auf euren Geräten hinterlegen müsst.
Mac
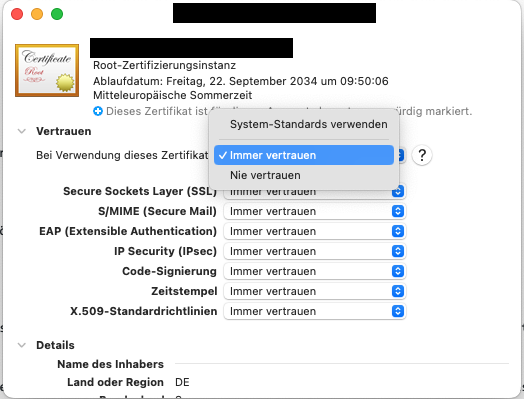
Auf dem Mac zieht man es einfach in die Schlüsselbundverwaltung. Anschließend öffnet ihr die Informationen zu diesem Zertifikat und stellt dort das Vertrauen auf “Immer vertrauen”.
iPhone/iPad
Schickt euch das Root CA Cert (“self-signed-ca-cert.crt”) per Airdrop oder anderweitig an das entsprechende Gerät. Anschließend öffnet/installiert ihr es auf dem Gerät und geht dann in: Einstellungen, Allgemein und dann “VPN und Geräteverwaltung” und installiert dort das neue Zertifikat final.
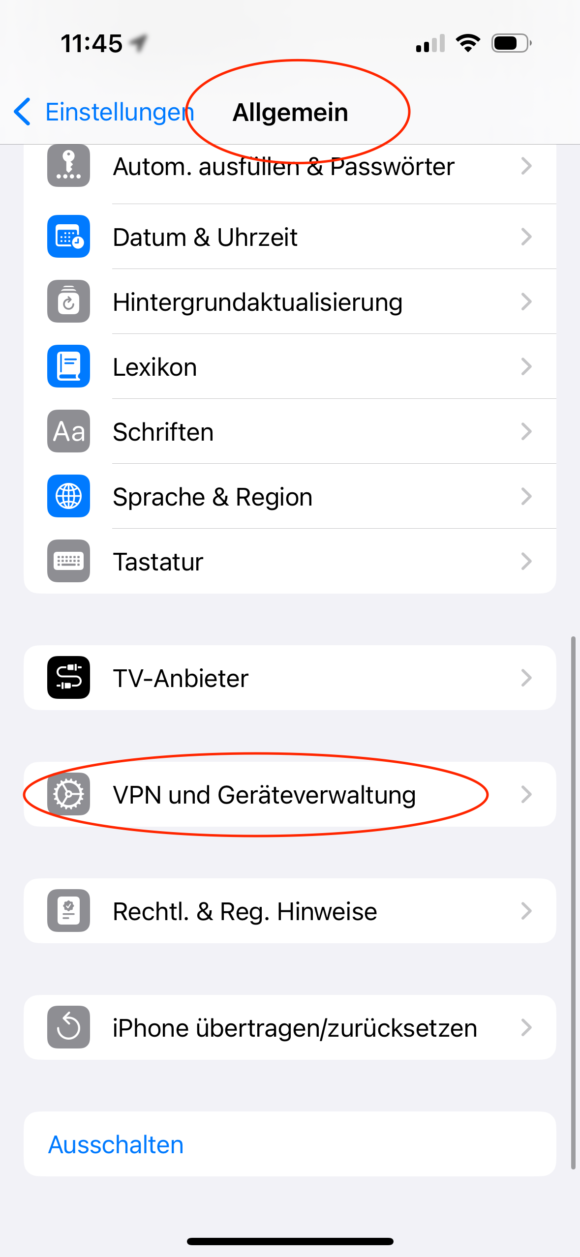
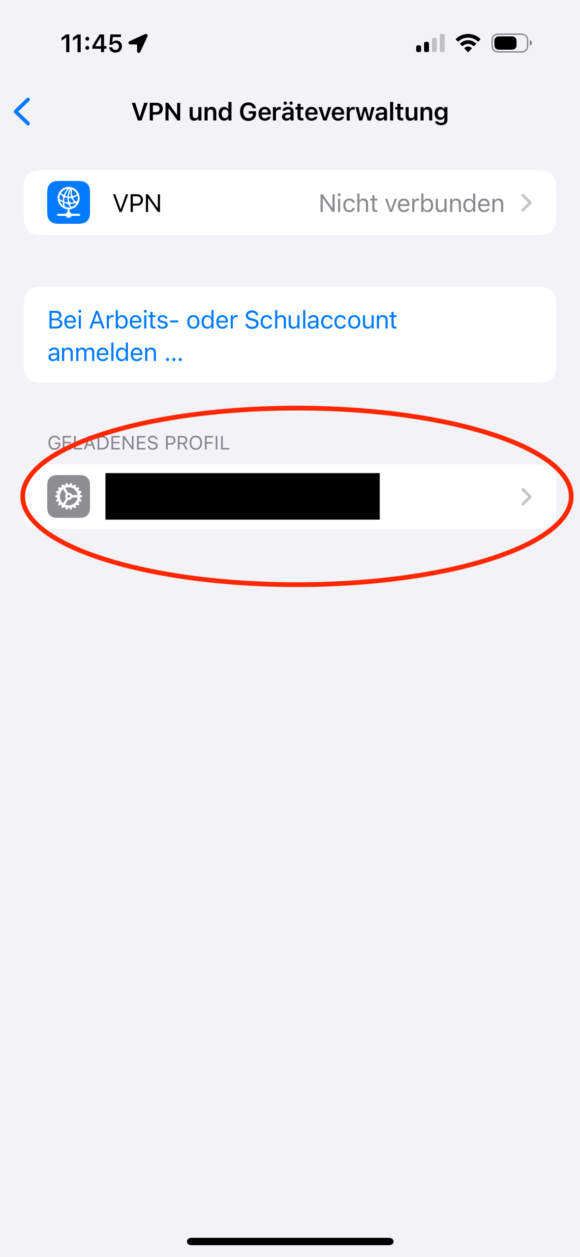
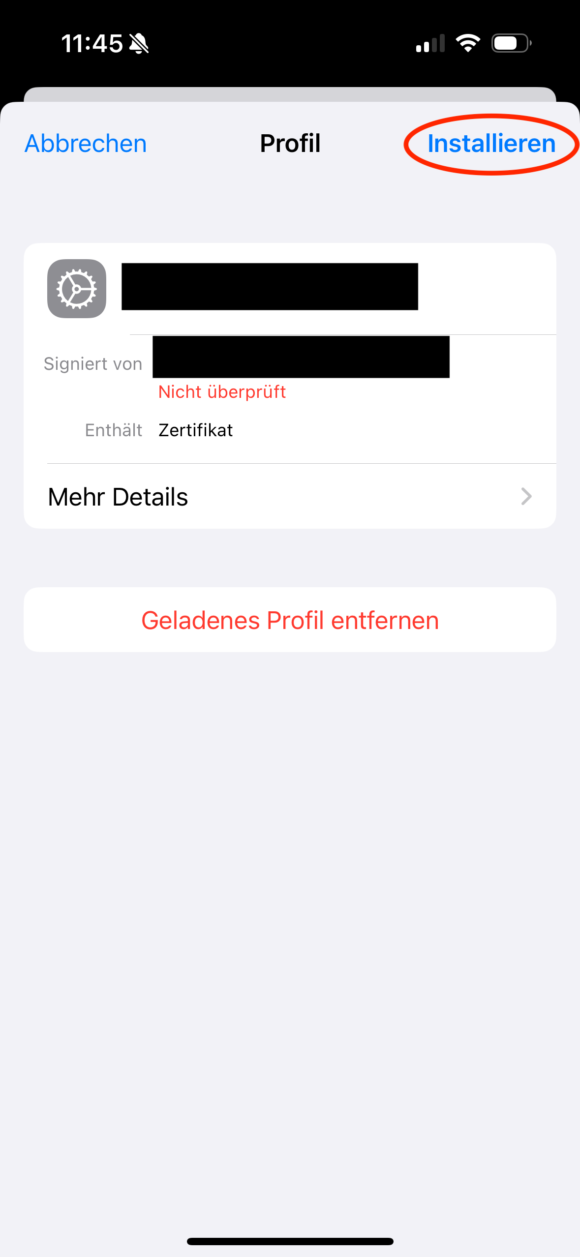
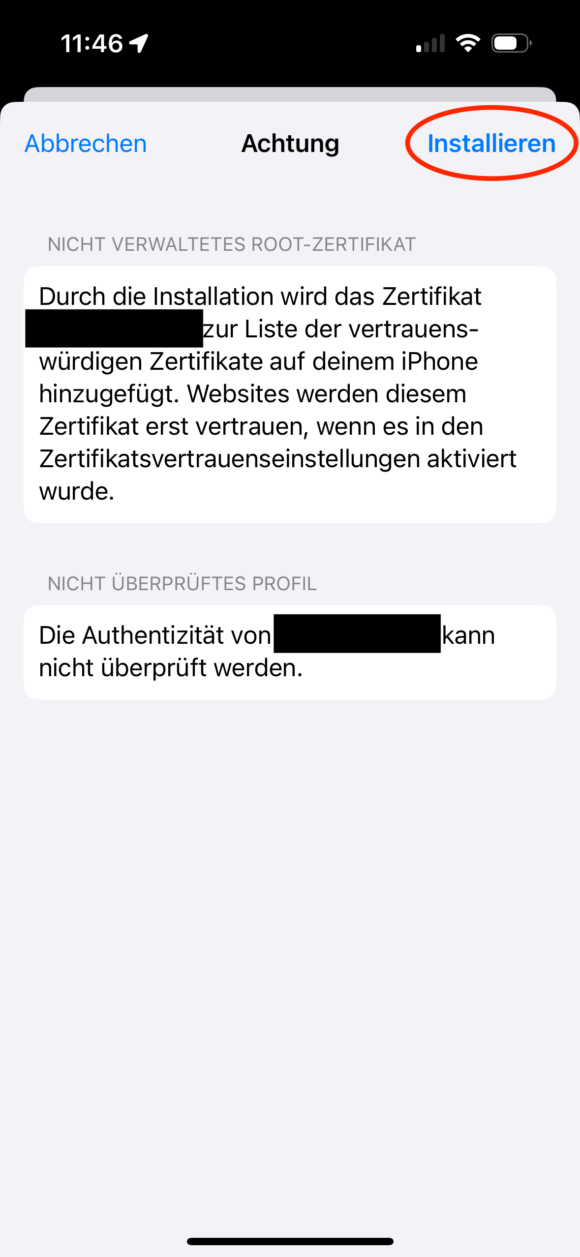
Anschließend muss dem neu installierten Zertifikat noch das Vertrauen ausgesprochen werden, was über Einstellungen, Allgemein, Info und dann “Zertifikatsvertrauenseinstellungen” erledigt wird:
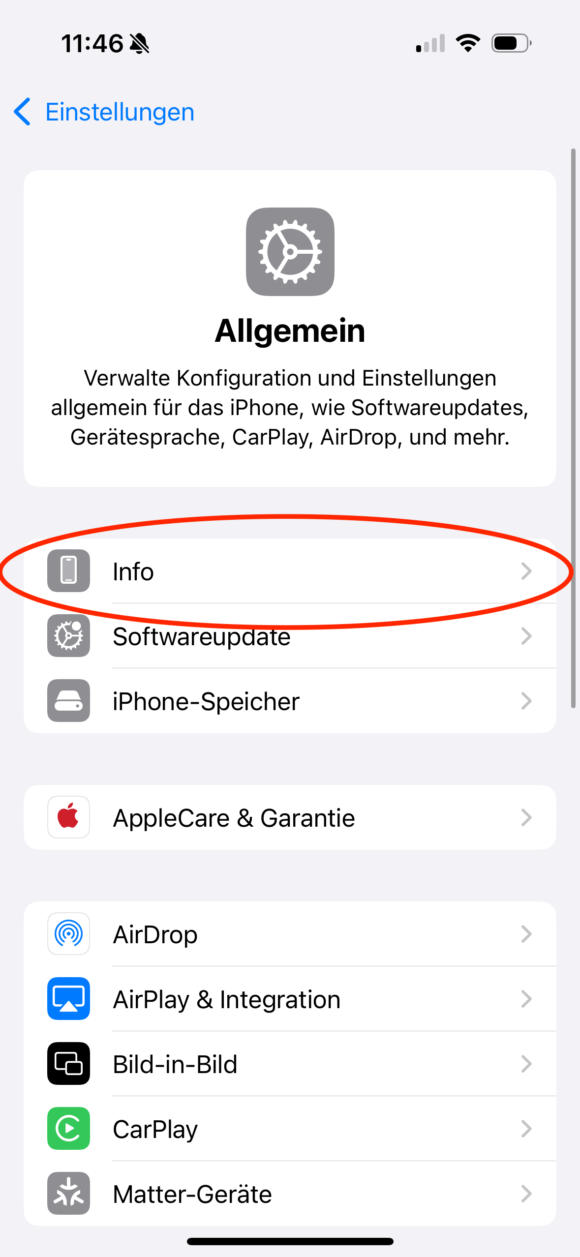
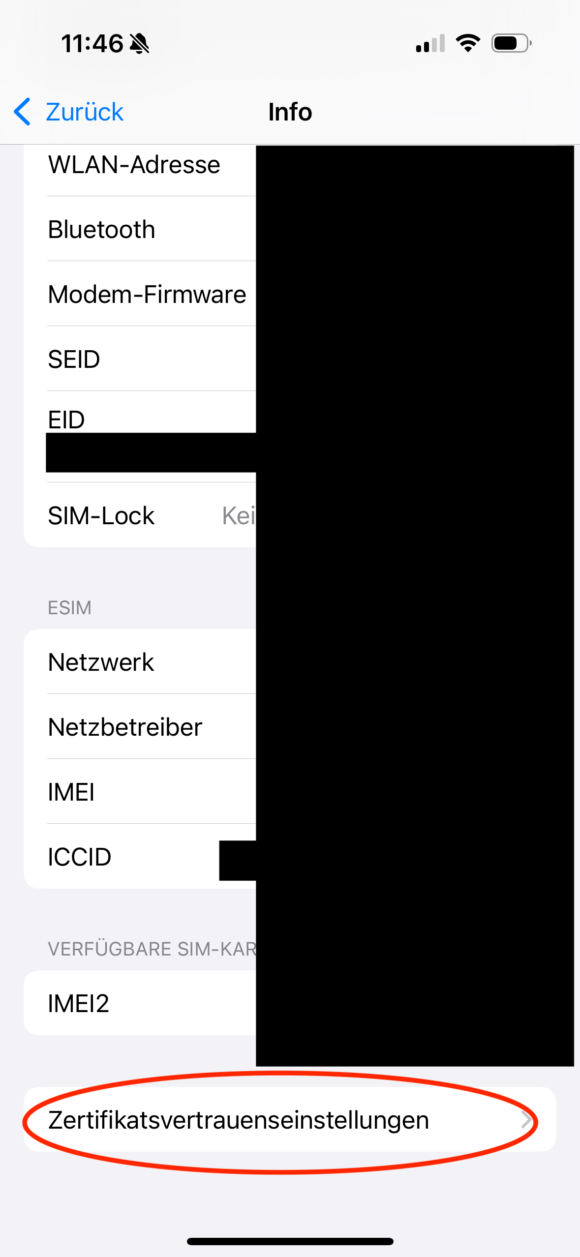
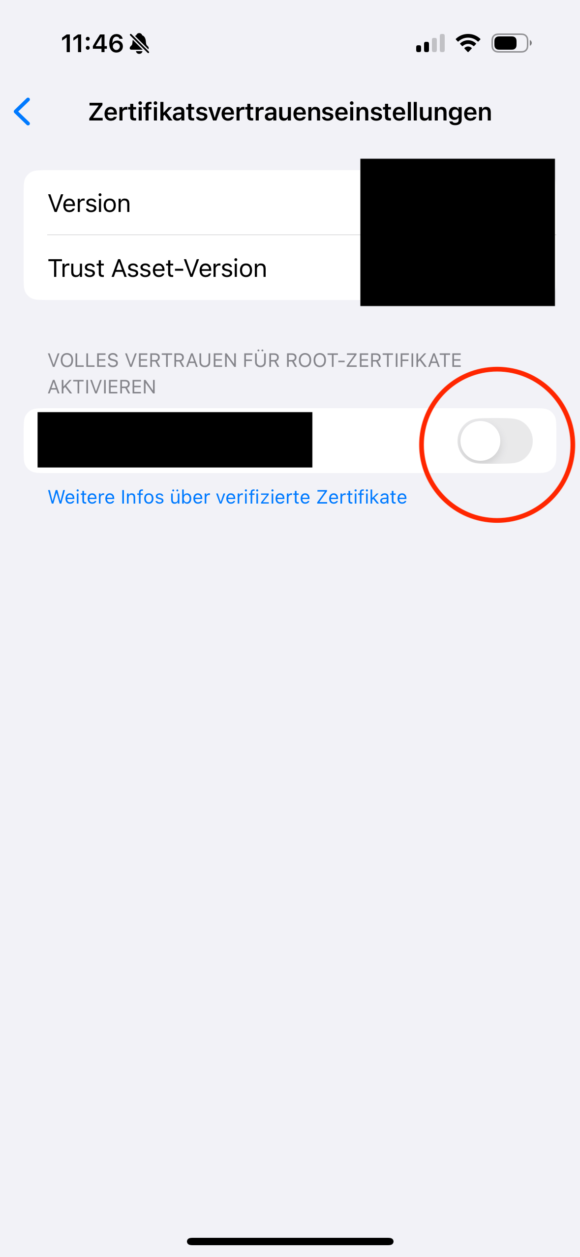
Wenn dieser Schalter aktiviert ist, dann werden ab sofort alle Zertifikate von dieser CA als vertrauenswürdig eingestuft, also auch eure Unterzertifikate.
Kubernetes
Als letzten Schritt muss nun noch das Unterzertifikat in eure Kubernetes Instanz eingespielt werden. Das geht über folgenden Befehl:
kubectl -n kube-system create secret tls default-ingress-cert --key=bytelude.key --cert=bytelude.crt --dry-run=client --save-config -o yaml | kubectl apply -f -
Zusätzlich müsst ihr noch folgende Ressource in eurem Kubernetes System entweder anlegen oder editieren:
apiVersion: traefik.containo.us/v1alpha1
kind: TLSStore
metadata:
name: default
namespace: kube-system
spec:
defaultCertificate:
secretName: default-ingress-cert
In meinem Fall ist Traefik der Default Ingress, bei Nginx könnte das Vorgehen evtl abweichen.
Nachdem all das erledigt ist, muss beim jeweiligen Service nur noch der Ingress so konfiguriert werden, dass er auch TLS/SSL spricht:
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: freshrss
namespace: freshrss
annotations:
kubernetes.io/ingress.global-static-ip-name: freshrss-ip
spec:
tls:
- hosts:
- freshrss.bytelude.intern
rules:
- host: freshrss.bytelude.intern
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: freshrss
port:
number: 80
Damit das funktioniert müsst ihr natürlich die entsprechende URL in eurem DNS (z.B. freshrss.bytelude.intern) hinterlegt haben. In meinem Fall habe ich in meinem Ubiquity Router einfach eine Wildcard DNS hinterlegen können, sodass alles was *.bytelude.intern ist auf die gleiche IP zeigt.
Wenn ihr nun alles richtig gemacht habt, dann sollte beim Aufruf von https://freshrss.bytelude.intern keine Sicherheits-Warnung kommen und das Schlosssymbol eures Browsers sollte auch geschlossen sein und somit eine sichere Verbindung vorhanden sein.
Wenn das eine Jahr herum ist und ihr ein neues Unterzertifikat erstellt habt, sollte ein erneutes Ausführen des Befehls
kubectl -n kube-system create secret tls default-ingress-cert --key=bytelude.key --cert=bytelude.crt --dry-run=client --save-config -o yaml | kubectl apply -f -
ausreichen, sodass ab sofort das neue Zertifikat verwendet wird. Damit sollte sich das ganze auch relativ einfach automatisieren lassen.